使用redisson做分布式锁时,使用最简单的单机模式,发现一个奇怪的问题,项目启动后刚开始获取和释放锁都没有什么问题,过一段时间后(5分钟左右,这个时间是后来发现的)就会出问题,看了日志显示如下图的RedisResponseTimeoutException,意思就是说redis响应超时,默认的超时时间是3秒钟,server在三秒钟内没有返回,所以报了这样一个错误。
提示:如果你在使用redisson客户端做分布式锁的时候遇到了
RedisResponseTimeoutException异常,而且你的客户端处于NAT环境,且你的redis服务器开启了密码认证,那么本文对你解决问题可能有帮助。
1 | |
看到这个异常,首先想到的原因就是redis server有问题,要么就是太忙碌了,造成响应缓慢,也有可能是网络的问题。先上服务器上看一眼,redis不是有慢查询日志吗,先看看是不是服务器的原因。
通过慢查询日志查找问题
redis server的慢查询日志需要首先配置一下,配置主要有两个,一个是时间阈值s,响应时间大于s的日志会被记录;另一个是日志最大长度L, 当记录的日志长度大于L时老的日志会被丢弃;
查看慢查询日志的最大长度
1 | |
设置慢查询日志的最大长度
1 | |
查看慢查询日志的时间阈值
1 | |
设置慢查询日志的时间阈值,这里设置为1秒,注意这里的时间单位是微秒,1秒等于10^6微秒
1 | |
都设置完成后,使用如下命令查看慢查询日志
1 | |
查看后发现慢查询日志里什么也没有出现,我还以为自己眼花了,但是试了好几次,依然如此,这就很奇怪了,没有请求,怎么还超时了呢?
一通搜索后,发现还有另外一个使用命令monitor可以监控服务器上收到的任何请求,使用这个命令试了试,确实看到了别的客户端发出的请求,但是还是没有我本地的这个redisson客户端发出的请求,就是如此诡异。
接下来只能怀疑是网络的问题了,先查看一下本地的TCP连接是否正常,
通过分析本地网络状态来查找问题
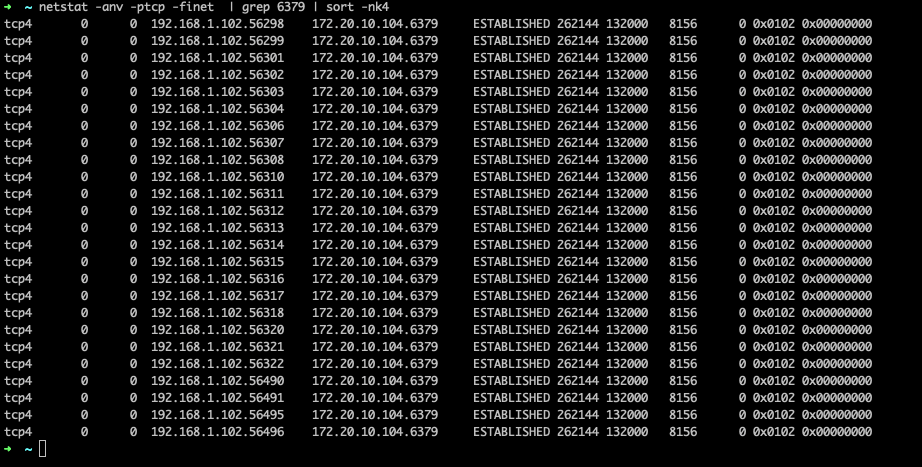
macos上使用netstat命令,格式稍与linux上不同,命令如下,sort对端口号这一列进行排序,这样看到的端口号是顺序的,很整齐
1 | |
看到如下结果,可以看到TCP连接都是ESTABLISHED状态,看起来很正常,有这么多连接是因为redisson客户端的连接池
接下来再使用Wireshark抓包看看请求是不是发出去了,结果如下图:
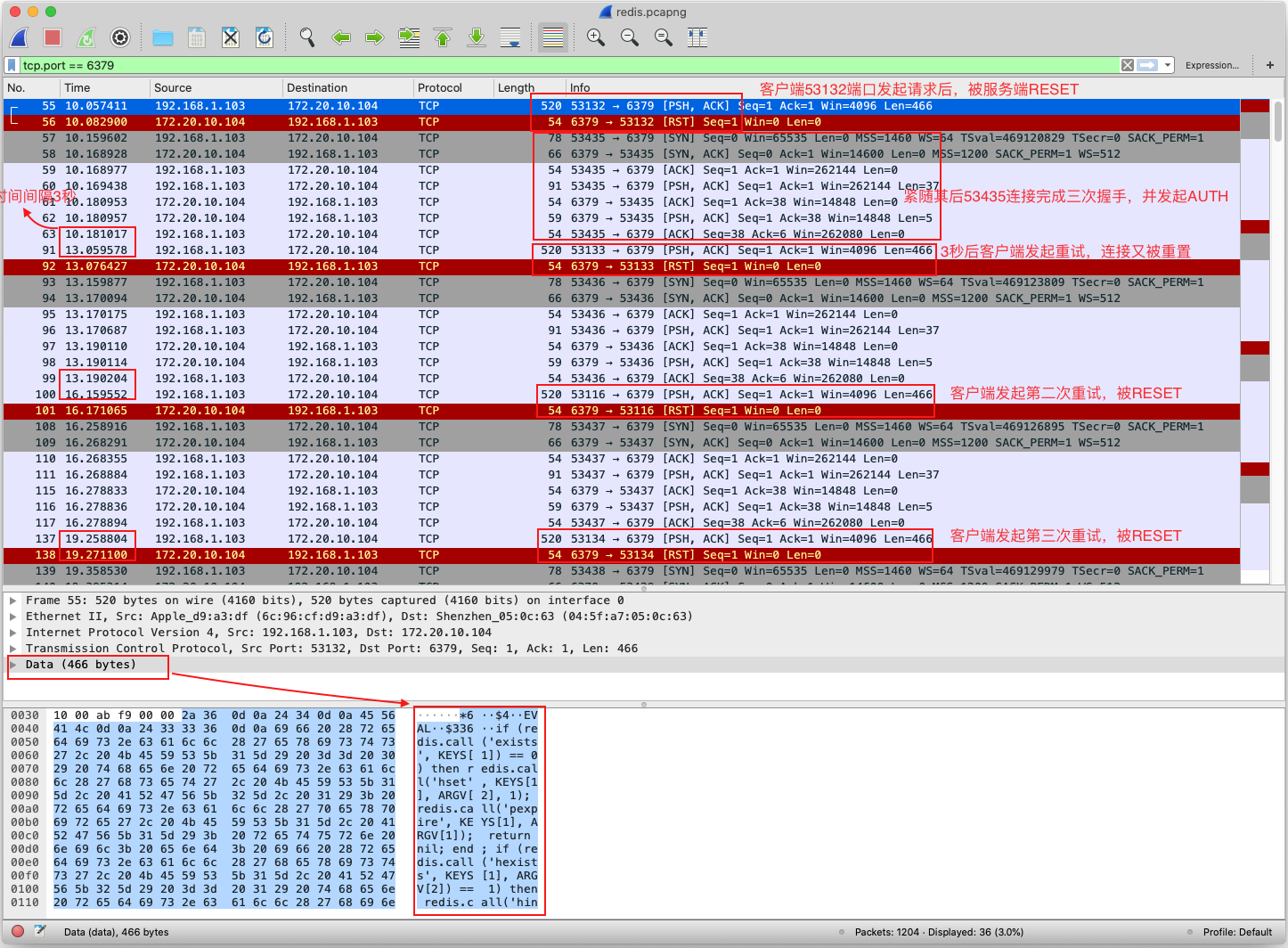
这张图里面信息量很大,仔细分析能看到很多东西,
图片第一行标号55,客户端53132端口发起了请求,请求的内容在图片的下面,是一串redis获取锁的命令,
第二行标号56,服务器6379端口回复了RST,表示异常关闭连接,关于RST报文后面会详细说明。
接下来的57-63号报文,是创建新的TCP连接并且进行密码认证的过程,具体说来,
第57-59号客户端53435和服务器端的6379端口进行了三次握手,完成了连接的创建,
第60号客户端从53435端口发起了AUTH password对连接进行认证(从TCP报文体可以看到,这里不再贴图),随便说一下AUTH的作用是认证连接,因为redis服务器设置了密码,认证通过的连接可以继续执行查询命令,否则服务器会拒绝执行。
第61号服务器端进行ACK表示收到了请求
第62号服务器回复OK表示认证成功
第63号客户端进行ACK表示收到,ACK报文是为了保证TCP连接不丢失数据,是可靠性的保证。
剩下的91-99号,100-117号以及137号之后的报文一直在重复上面的情况,一共重复3次。
解释一下客户端收到RST后会重新建立一个新连接的原因是redisson使用了netty,netty中的设置使得发现TCP连接异常会重新建立新连接;报文重复三次的原因是reddison默认的重试机制,失败后重试三次。
关于RST报文的说明
我们知道正常关闭一个连接是通过一个四次挥手的过程,但是异常情况下,服务器端会直接回复RST来关闭连接,不需要进行ACK,具体的异常情况博主在网上找到一篇文章,下面是截图,原文连接放在文末

看了这段话,很受启发,难道说客户端TCP连接的状态是ESTABLISHED是一种假象吗,可能在服务器端连接已经断开了,只不过这种状态没有同步到客户端来,而且正如文章作者所言,我本地开发环境处在一个NAT环境中,因为中间有一个路由器设备,图片中博主的地址是192.168.1.103,本地NAT出口的地址是172.20.169.241,服务器端地址是172.20.10.104
确认服务器上的TCP状态
在linux服务器上查看连接状态(截图是后来截的,和前面截图上的端口号对应不上)

可以看到服务器上只有四个连接,这四个连接刚好是新创建的连接,也就是说在这之前,服务器端和客户端是没有连接的,至此可以确定是服务器端断开了连接,但是两边没有同步。
接下来我们对服务器端抓包看看是不是这样
在linux服务器上我们使用tcpdump抓包,然后下载到本地使用wireshark进行分析,命令如下
1 | |
结果如图

可以看到服务器端在290秒的时候向客户端批量发送ACK,然后被客户端直接RST,那客户端为什么在290秒左右批量发起ACK呢,我查询了一下redis server的配置文件,里面有一条配置tcp keepalive是300秒,所以猜测应该是服务器端为了做keepalive主动发起和客户端的通信,客户端则回应RST关闭了该连接,这里肯定是中间的路由器干的,报文根本就没有被转发到真的客户端192.168.1.103,看来简单粗暴才是这是事故的根本原因啊,真凶找到了就是中间的低端路由器。
1 | |
分析到这里情况已经很清楚了,那么该如何防止这种情况呢,经过测试可以设置setPingConnectionInterval这个配置,通过客户端主动向服务器发送PING命令来维持连接,博主还专门测试了setKeepAlive这个配置发现单独启用这个配置没有作用。
简单的一个配置代码如下:
1 | |
最后的结论:处于NAT网络环境中,可能会出现这种无法保持两端TCP连接的情况。
总结一下:之所以发生这个异常,是几个机缘巧合叠加在一起的结果,首先你的redis server得开启了密码认证,其次你的客户端需要处于NAT环境中。你说这是redisson客户端的bug吗,好像也不干人家什么事。
参考:
https://cloud.tencent.com/developer/news/209381